몬테카를로 학습 (MC)
정확한 수학 수식에 의해 계산/측정 하는 것이 아닌,
확률적인 방법에 의해 값을 통계적으로 계산하는 것
보상 함수와 전이 확률을 알 때,
DP를 사용하여 전체 상태를 한 번씩 모두 실행하며 각 상태의 가치를 업데이트 했음
몬테카를로 학습에서는 하나의 에피소드가 끝날 때까지 실행하면서
경험을 모으고, 그 경험으로부터 가치 함수를 계산함
정확한 결과를 얻기보다는 근사적인 결과를 얻을 경우에 사용몬테카를로 학습의 전제조건
단 하나의 전제조건이 필요한데,
에이전트가 동작하는 환경에 시작과 끝이 있어야 한다.
리니지, 메이플스토리처럼 MMORPG의 경우 엔딩이 없이 쭉 이어지는 게임이지만,
디아블로와 같은 게임은 에피소드 단위로 게임이 진행되어 에피소드마다 엔딩이 있다.
-> 디아블로는 MC 적용 가능몬테카를로 학습 알고리즘

N(s) = 상태 s에서 총 몇 번 방문했는지 횟수를 기록
V(s) = 상태 s에서 경험했던 리턴의 총합을 기록
- 테이블 초기화
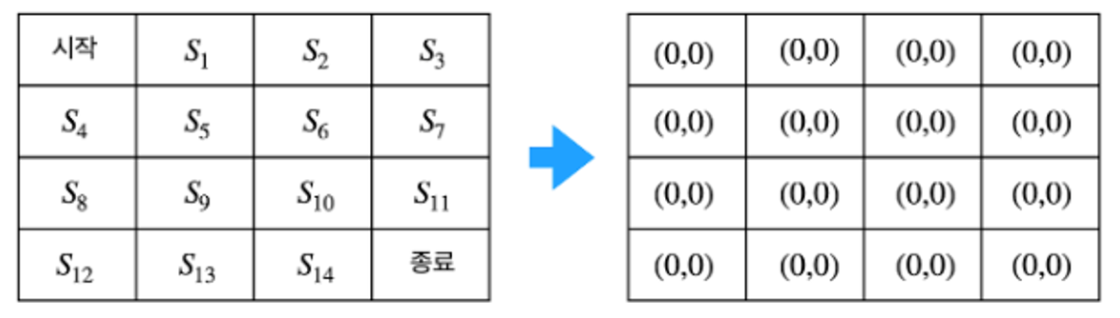
N(s)와 V(s)를 0으로 초기화- 경험 쌓기
에이전트가 시작(S0)에서 종료(St)에 도달하기까지의 에피소드를 실행
에피소드에 대한 리턴을 계산함- 테이블 업데이트
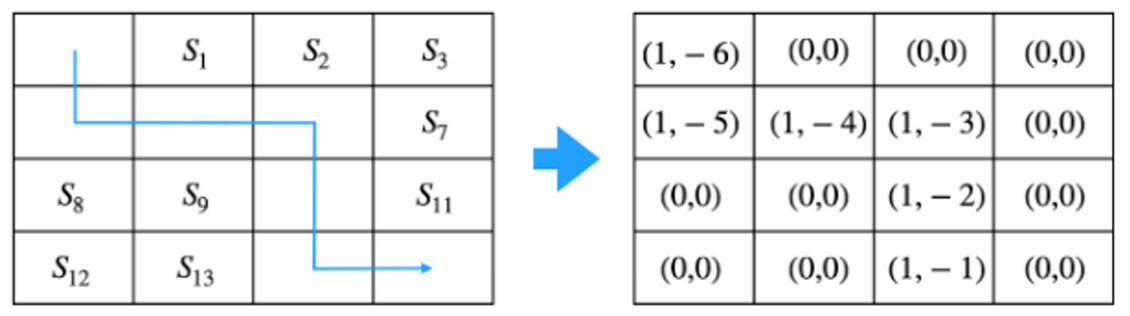
하나의 에피소드: s0 → s4 → s5 → s6 → s10 → s14 → sT
방문했던 모든 상태에 대해 N(s)와 V(s)값을 업데이트
N(St) = N(St) + 1
V(St) = V(St) + Gt벨류 계산
많은 횟수의 에피소드를 경험 후 충분히 경험이 쌓이면,
리턴의 평균을 밸류의 근사치로 사용
조금씩 업데이트하는 버전

- 에피소드가 1개 끝날 때마다 테이블의 값을 조금씩 업데이트
- 알파는 얼만큼 업데이트할 지 크기를 지정
- N(St)에 값을 저장해둘 필요 없이 에피소드가 끝날 때마다 테이블의 값 업데이트
Temporal Difference (TD)
몬테카를로의 단점
몬테카를로는 업데이트를 하려면 반드시 에피소드가 끝난 후에 리턴을 계산해야 한다.
-> 적용할 수 있는 환경이 제한적
-> 학습을 느리게 함TD
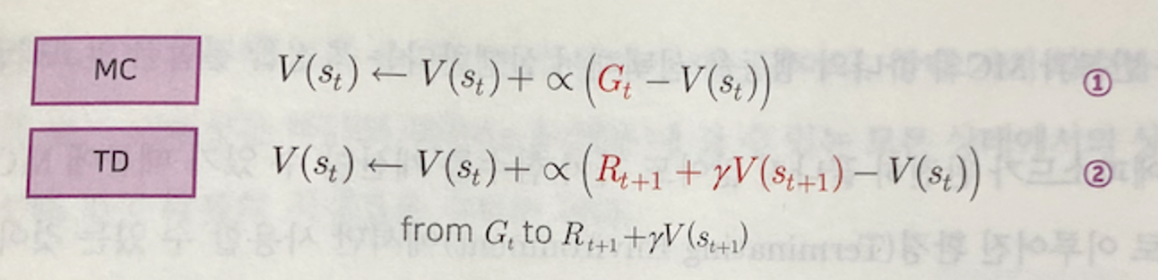
시간차 학습
에피소드가 끝나기 전에 업데이트를 하자
추측을 추측으로 업데이트 하자
MC에서 하나의 에피소드가 끝날 때 얻을 수 있는 리턴을
하나의 타임스텝이 완료되면 얻을 수 있게 표현해보면 2번과 같이 된다.
다음 타입스텝에서 즉시 얻을 수 있는 가치 = R(t+1)
계산에 의해 얻을 수 있는 가치 = r * V(s(t+1)MC와 TD 비교
DP | MC | TD
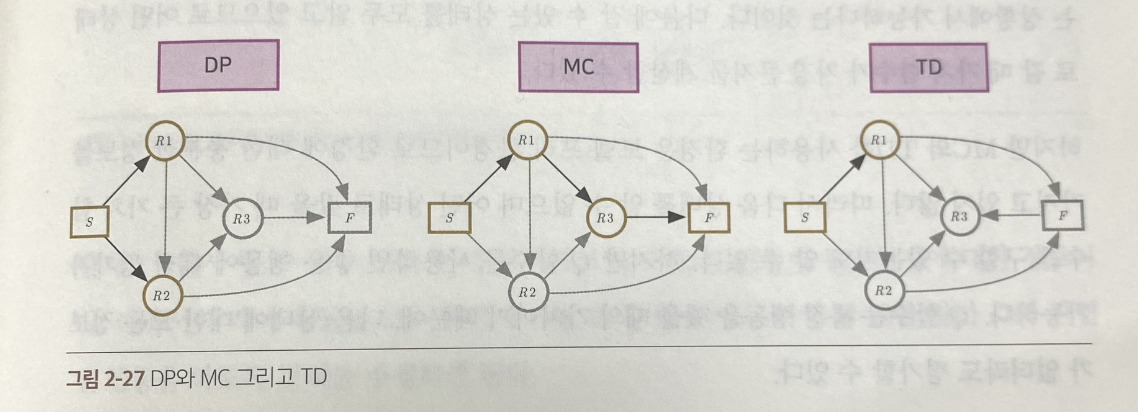
학습 시점에서의 비교
- 종료 상태가 있는 경우
= MC, TD 모두 적용 가능 - 종료 상태가 없거나, 하나의 에피소드가 너무 긴 경우
= TD만 적용 가능
편향성
- MC
- 여러 개의 샘플에 대한 평균을 구하므로, 편향되지 않음
- TD

편향성 측면에서는 MC가 더 좋음
분산
MC - 에피소드가 끝나야 리턴이 되므로 다양한 값을 가짐
MC = 분산이 큼
TD - 한 샘플만 보고 업데이트하므로 분산이 적음
분산의 측면에서는 TD가 우세
프로그램 구현
몬테카를로 학습 구현
그리디 월드로 몬테카를로 예측을 구현하기 위해
4가지의 요소가 구현되어야 한다.
- 환경: 에이전트의 액션을 받아 상태 변이를 일으키고, 보상을 줌
- 에이전트: 4방향 랜덤 정책을 이용해서 움직임
- 경험 쌓는 부분: 에이전트가 환경과 상호작용하며 데이터를 추적
- 학습하는 부분: 쌓인 경험을 통해 테이블을 업데이트
- 보상은 -1로 고정
'🎸 기타 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Deep RL 첫 걸음 (0) | 2024.06.05 |
|---|---|
| [RL] MDP를 모를 때 최적의 정책 찾기 (1) | 2024.06.03 |
| [RL] MDP를 알 때 플래닝 (0) | 2024.05.23 |
| [RL] 벨만 방정식 (0) | 2024.05.20 |
| [RL] 마르코프 보상 과정 (MRP) | 마르코프 결정 과정 (MDP) (0) | 2024.04.30 |