우리가 해온 것들은 데이터 개수가 적은 간단한 경우였다.
따라서 테이블 기반 방법론으로 동작해도 문제가 없었다.
그러나, 바둑과 체스 등과 같이
상태의 경우의 수가 많은 문제에서 테이블 기반 방법론은 적용하기 어렵다.
바둑이나 체스처럼 이산적(discrete)인 형식이 아닌 속도와 같이 연속적인 값을 가질 수 있음.
함수의 등장
테이블 기반 방법론을 사용하지 않고,
위 사진의 함수에 저장
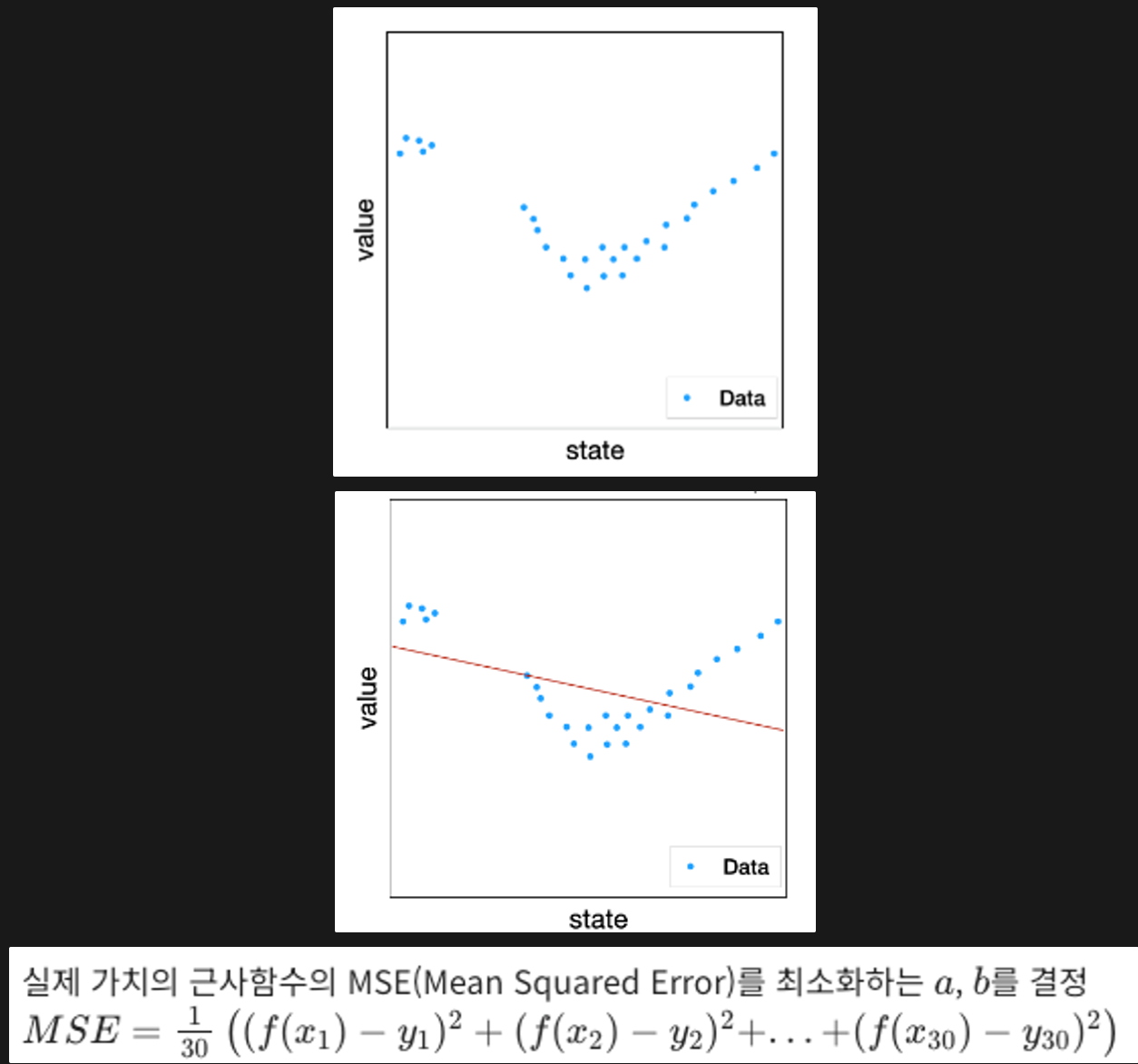
실제 가치의 근사함수
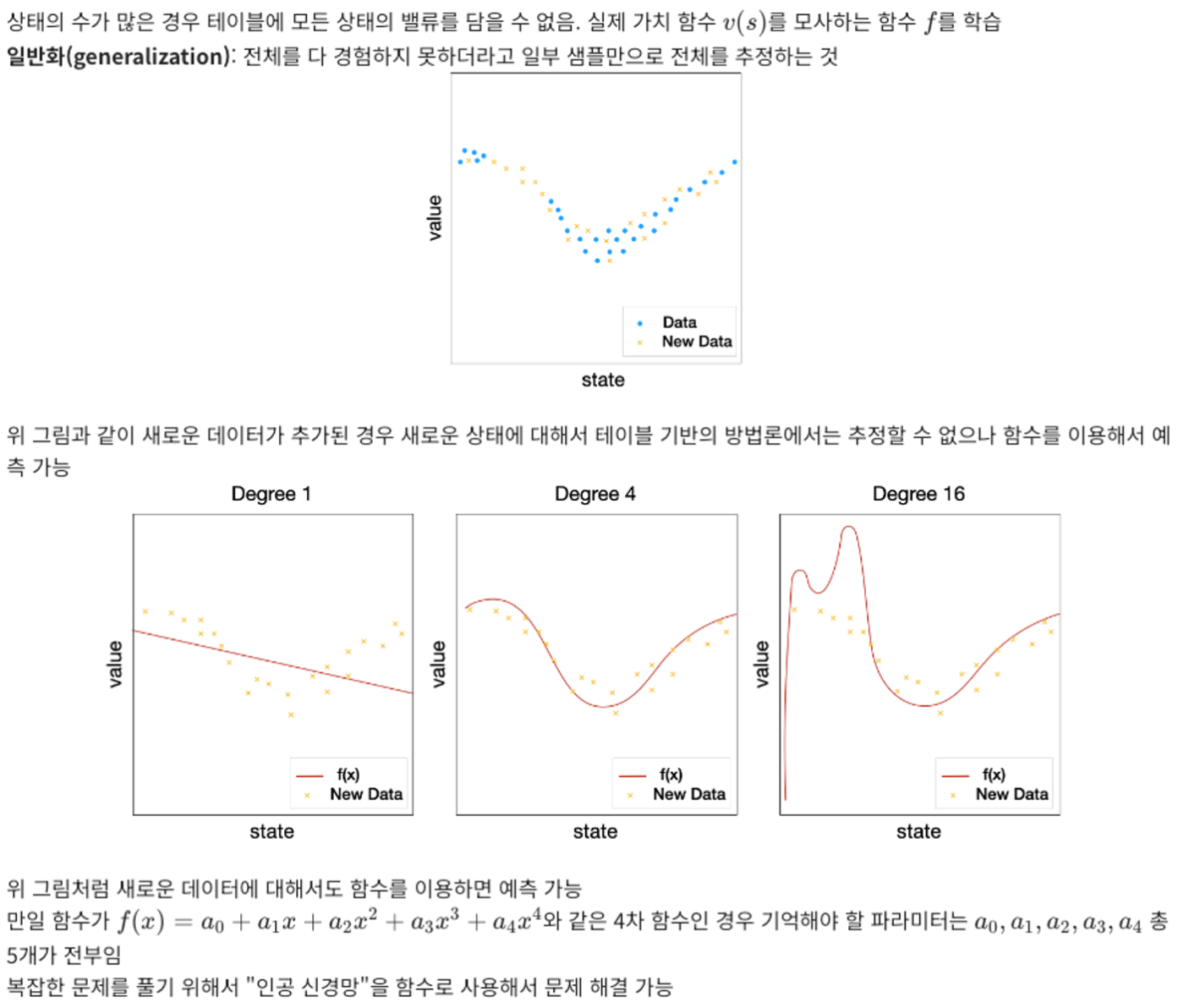
데이터가 많은 경우
위 그림과 같이 MSE를 최소로 하는 a, b를 결정
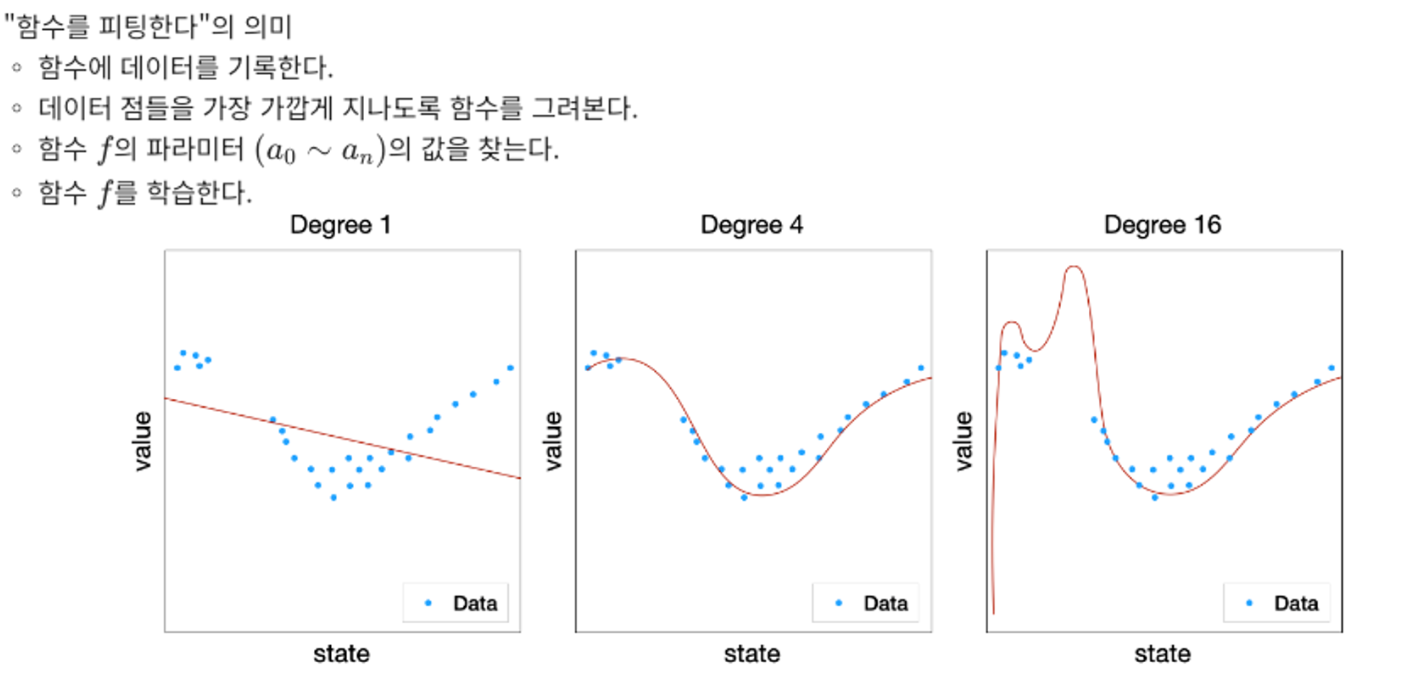
함수의 복잡도에 따른 차이
1차함수의 경우 데이터 양이 많아지면 데이터를 표현하기에 어려움이 있음
1차 함수가 아닌 다항 함수를 사용할 수 있음
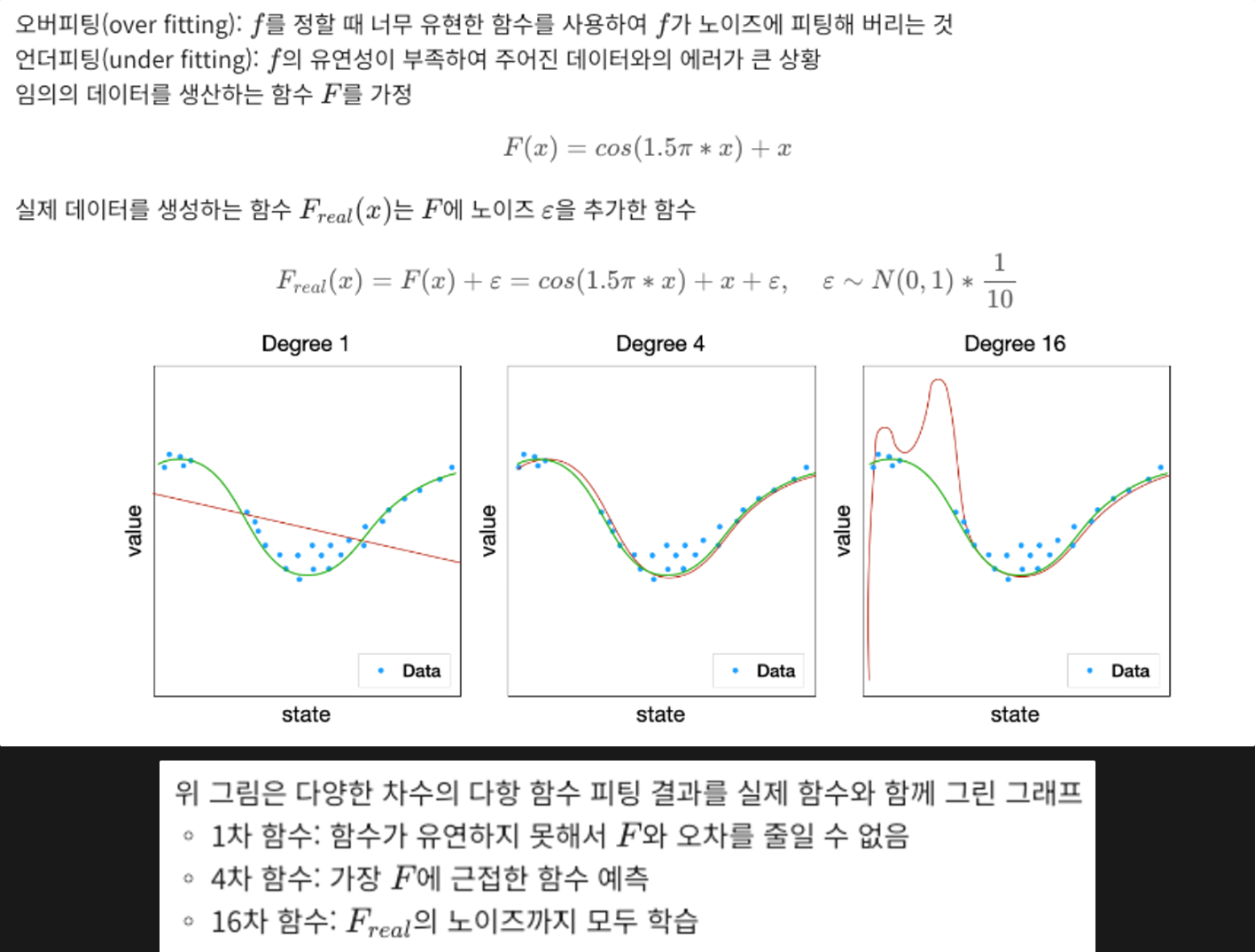
위 그림에서 고차함수로 갈수록 MSE는 감소하지만 데이터에 노이즈가 석여 있음
노이즈: 각각의 에피소드를 경험할 때 얻은 값은 노이즈가 있는 "틀린" 값이고 샘플이 충분히 모였을 때 그 평균이 실제 정답에 가까워짐
오버 피팅과 언더 피팅
함수의 장점 - 일반화
함수를 일반화 함으로써 함수의 파라미터만 기록하면 된다.
테이블 기반 방법론은 모든 상태를 기록했는데, 이와 상반된다.
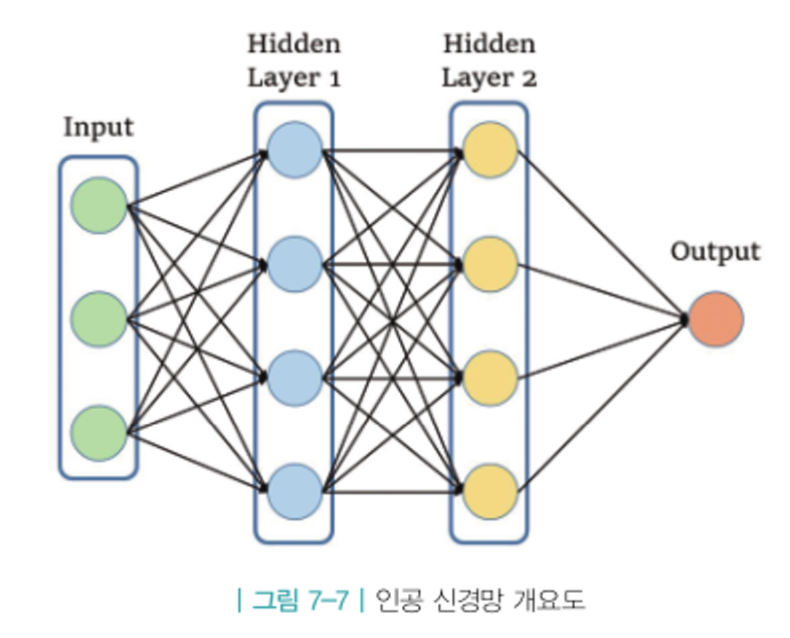
7.2 인공 신경망의 도입
신경망
신경망의 본질은 매우 유연한 함수이다.
함수에 포함된 프리 파라미터의 개수를 통해 함수의 유연성을 제어한다.
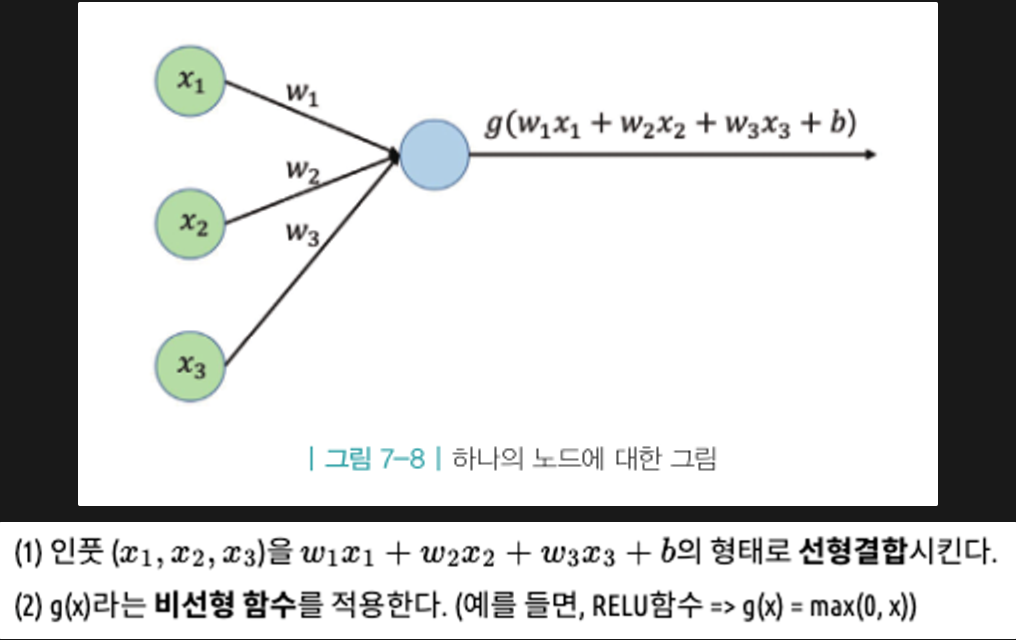
여기서 선형결합의 의미는 인풋값들을 조합하여 새로운 피처(특징값)를 만드는 과정
또한 비선형함수 적용은 인풋과 아웃풋의 관계가 비선형일 수 있기에 필요한 과정
신경망 학습 - 그라디언트 디센트
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
class Model(tf.keras.Model):
def __init__(self):
super(Model, self).__init__()
self.fc1 = tf.keras.layers.Dense(128, activation='relu')
self.fc2 = tf.keras.layers.Dense(128, activation='relu')
self.fc3 = tf.keras.layers.Dense(128, activation='relu')
self.fc4 = tf.keras.layers.Dense(1, use_bias=False)
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc4(x)
return x
def true_fun(X):
noise = np.random.rand(X.shape[0]) * 0.4 - 0.2
return np.cos(1.5 * np.pi * X) + X + noise
def plot_results(model):
x = np.linspace(0, 5, 100)
input_x = tf.convert_to_tensor(x, dtype=tf.float32)
input_x = tf.expand_dims(input_x, axis=1)
plt.plot(x, true_fun(x), label="Truth")
plt.plot(x, model(input_x), label="Prediction")
plt.legend(loc='lower right', fontsize=15)
plt.xlim((0, 5))
plt.ylim((-1, 5))
plt.grid()
def main():
data_x = np.random.rand(10000) * 5
validation_x = np.linspace(0, 5, 100)
validation_y = true_fun(validation_x)
model = Model()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
mse_loss = tf.keras.losses.MeanSquaredError()
train_losses = []
val_losses = []
for step in range(10000):
batch_x = np.random.choice(data_x, 32)
batch_x_tensor = tf.convert_to_tensor(batch_x, dtype=tf.float32)
batch_x_tensor = tf.expand_dims(batch_x_tensor, axis=1)
batch_y = true_fun(batch_x)
truth = tf.convert_to_tensor(batch_y, dtype=tf.float32)
truth = tf.expand_dims(truth, axis=1)
with tf.GradientTape() as tape:
pred = model(batch_x_tensor)
loss = mse_loss(truth, pred)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_losses.append(loss.numpy())
if step % 100 == 0:
val_x_tensor = tf.convert_to_tensor(validation_x, dtype=tf.float32)
val_x_tensor = tf.expand_dims(val_x_tensor, axis=1)
val_pred = model(val_x_tensor)
val_loss = mse_loss(tf.convert_to_tensor(validation_y, dtype=tf.float32), val_pred)
val_losses.append(val_loss.numpy())
print(f"Step {step}, Training Loss: {loss.numpy()}, Validation Loss: {val_loss.numpy()}")
plt.figure(figsize=(12, 6))
plt.plot(train_losses, label='Training Loss')
plt.plot(np.arange(0, 10000, 100), val_losses, label='Validation Loss')
plt.xlabel('Step')
plt.ylabel('Loss')
plt.legend()
plt.grid()
plt.show()
plot_results(model)
plt.show()
if __name__ == "__main__":
main()