MDP를 모를 때 최적의 정책찾기
몬테카를로 컨트롤
정책 이터레이션을 그대로 사용할 수 없는 이유

정책 이터레이션 리뷰
정책 이터레이션은 정책 평가와 정책 개선 두 단계로 구성 정책 평가: 고정된 정책 𝜋에 대해 각 상태의 가치를 구함 = 반복적 정책 평가 = 밸류 평가 정책 개선: 정책 평가의 결과에 따라 새로운 정책 𝜋'를 생성 = 그리디 정책 생성 반복적 정책 평가와 정책 개선을 진행하면 정책과 가치가 변하지 않는 단계에 도달하게 됨 -> 최적 정책과 최적 가치
- 반복적인 정책 평가를 사용할 수 없음
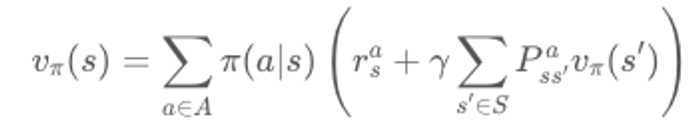
모델 프리 상황에서는 보상함수 r과 전이확률 P를 모르기 때문에
위 벨만 기대 방정식 2단계를 사용할 수 없음 
정책 개선 단계에서 그리디 정책을 만들 수 없음
지난 주를 통해 각 상태의 가치를 알더라도, 전이확률 P를 모르기 때문에
액션을 취했을 때 어떤 상태에 도달했는지를 알 수가 없음
정책 이터레이션 불가능의 해결방법
정책 평가 단계에서 MC를 이용
→ 몬테카를로를 이용해서 q(s, a)를 구할 수 있음
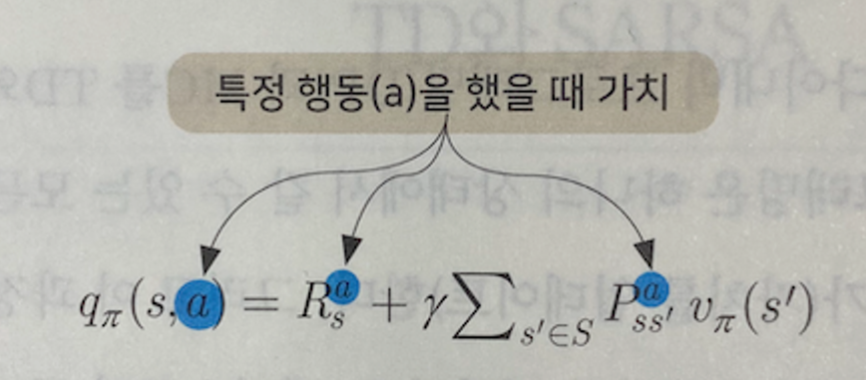
V(상태가치함수) 대신에 Q(행동가치함수)를 사용
```swift
어떤 상태로 갔을 때 가장 큰 가치 함수를 구할 수 있는 지 모름
-> Q 함수 사용 시 좋은 행동에 대한 평가가 가능
특정 행동을 했을 때의 가치이기 때문에,
다음 상태에 대한 모든 정보가 없더라도 평가가 가능하다.
```
```swift
밸류 v(s) 대신, 상태-액션가치 함수 q(s, a)를 사용
-> MC를 이용하여 q(s, a) 함수를 계산
-> 평가된 q(s, a)를 이용하여 새로운 그리디 정책을 생성
-> 위 두 과정을 반복
단, 위 방법은 새로운 길을 탐색하지 못하므로 최적의 해를 찾지 못할 수 있음
```- greedy 대신 𝜖 - greedy (앱실론 그리디)

- 𝜖이라는 작은 확률만큼 랜덤하게 액션을 선택
나머지 1 - 𝜖 확률은 원래 그리디를 선택$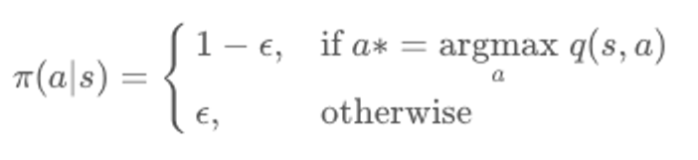
- Decaying 𝜖 - greedy
: 처음에는 𝜖 값을 크게 하고, 이후 점점 줄이는 방식몬테카를로 컨트롤 구현
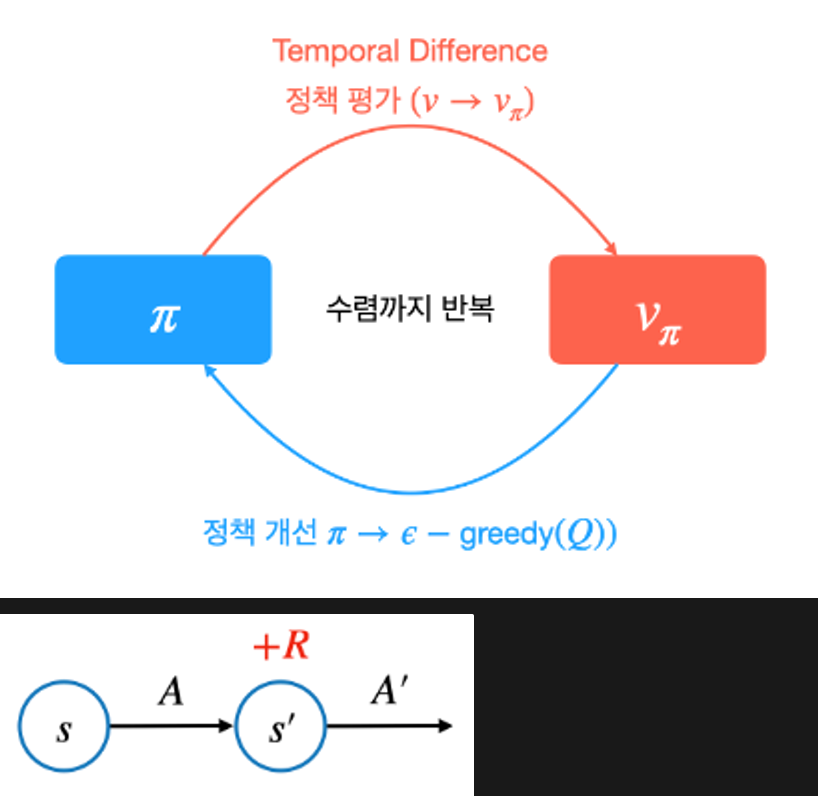
TD 컨트롤 1 - SARSA (살사)
MC 대신 TD를 사용한다면 ?
Q 함수에는 행동과 상태에 대한 가치가 모두 있음
즉, Q 함수를 가지고 정책을 평가하고, 동시에 정책 제어를 함
Q 함수는 상태 S일 때, A 행동을 하고 보상 R을 받음
다음 상태 S'에서 A' 행동을 하면 R'가 나옴
... 계속 반복하면 SAR SAR SAR를 하게 된다.
즉, SARSA 라는 이름이 붙었다.
= TD를 이용하여 Q를 계산하는 접근 방법SARSA

◦ TD로 V 학습: 𝑉(𝑆)←𝑉(𝑆)+𝛼(𝑅+𝛾𝑉(𝑆′)−𝑉(𝑆))
◦ TD로 Q 학습 (SARSA): Q(S,A) ← Q(S,A) + α(Rt+1 + 𝛾Q(S′, A′)−Q(S,A))
Q함수를 최대로 하는 행동을 선택하도록 업데이트
TD 컨트롤 2 - Q러닝
On-Policy와 Off-Policy
타깃 정책과 행동 정책
타깃 정책 - 강화하고자 하는 목표가 되는 정책
행동 정책 - 실제로 환경과 상호작용하며 경험을 쌓고 있는 정책On-Policy와 Off-Policy
온 폴리시 (직접 경험)
: 타깃 정책 == 행동 정책
오프 폴리시 (간접 경험)
: 타깃 정책 != 행동 정책
여태껏 우리가 공부한 내용은 '온 폴리시'
정책을 평가하는데 사용되는 정책(파이)와 정책을 제어하는데 사용하는 정책
두 정책이 모두 같기 때문임On-Policy의 문제점
On-Policy의 TD
한 타임스텝을 더 가서 상태 가치함수를 계산 후 정책을 평가했다.
Q함수에서 탐욕적으로 정책을 수정하며, 이 과정을 반복함
-> 한 번 평가에 사용했던 경험은 나중에 재사용되지 못함
-> 정책을 항상 탐욕적으로 선택하기에 다양한 정책을 적용하지 못함
이 해결책이 Off-PolicyOff-Policy 학습의 장점
1. 과거의 경험을 재사용할 수 있음
초기 정책함수 = π0
(s, a, r, s')의 동작을 100번 경험하여 π1로 업데이트
(s, a, r, s') = SARSA의 상태 s에서 액션 a 했더니 보상 r을 받고 상태 s'에 도달
여기서 On-Policy 라면 ?
π1을 학습하려면 π0과는 새로운 정책이기 때문에
타깃 정책 = π1 에다가 행동 정책 π0을 적용할 수 없음
π1을 이용해서 경험을 다시 처음부터 쌓아야 함
π0과 π1은 차이가 미비할 지라도, 엄연히 서로 다른 정책
100번 경험한 것은 π0
π1을 업데이트 하려면 다시 쌓아야 했음
그러나, Off-Policy의 경우
타깃 정책과 행동 정책이 달라도 되기 때문에 π0의 내용을 재사용할 수 있음2. 사람의 데이터로부터 학습할 수 있음
Off-Policy 방법론의 행동 정책에는 어떠한 정책을 가져다 놔도 됨
행동 정책과 타깃 정책 사이의 차이에 따라
학습의 효율성이 달라질 수 있으나, 환경과 상호작용하며 경험을 쌓는다면 상관 X
프로 바둑 기사가 뒀던 기보라도
(s, a, r, s')로 이루어진 데이터만 있다면 학습에 쓸 수 있음3. 1:N, N:1 학습이 가능
- 동시에 여러 개의 정책이 겪은 데이터를 모아서 1개의 정책을 업데이트 가능
- 행동 정책과 타깃 정책이 달라도 되기에 다양한 관점에서 학습 가능
Q러닝 이론적 배경

빨간색의 글자 부분이 Q러닝과 SARSA의 업데이트 식 차이점
벨만 최적 방정식 0단계를 통해 Q 러닝의 식을 도출함
Q 러닝에서 경험을 쌓을 때 다음 행동은
정책을 따라가는 것이 아니라, Q 값을 max로 만드는 행동을 선택
SARSA: 행동 정책 == 타깃 정책 -> On-Policy
Q러닝: 행동정책 != 타깃 정책 -> Off-Policy
SARSA는 On-Policy 방식이고, Q러닝은 Off-Policy 방식SARSA와 Q러닝이 다른 이유

기초가 되는 수식이 다르기 때문이다.
Q 러닝은 벨만 최적 방정식이므로, 환경에 존재하는 최적의 정책을 고대함
환경에 의존적이지만, 환경이 잘 정해지면
그에 따라 최적 정책도 정해진다.
환경을 충분히 잘 탐험한다면 최적 정책을 찾을 수 있고,
여기서 환경을 탐험하는데 사용하는 정책은 어떠한 정책이어도 상관없다.'🎸 기타 > Reinforcement Learning' 카테고리의 다른 글
| [RL] 가치 기반 에이전트 (2) | 2024.06.14 |
|---|---|
| [RL] Deep RL 첫 걸음 (0) | 2024.06.05 |
| [RL] MDP를 모를 때 밸류 평가하기 (1) | 2024.06.02 |
| [RL] MDP를 알 때 플래닝 (0) | 2024.05.23 |
| [RL] 벨만 방정식 (0) | 2024.05.20 |