Web and HTTP
웹 Web
객체들로 구성됨
웹 페이지는 여러 참조 객체를 포함하는 base HTML 파일
각 객체는 URL로 주소 지정 가능
HTTP 개요
Stateless, 과거에 대한 정보 X
HTTP Message는 Request | Response 2가지 종류
ASCII 코드 형식이다.
포트번호 80 사용
HTTP 1.0 (비지속 연결)
- 클라이언트가 TCP 연결 요청
- 서버가 TCP 연결 승인
- 클라이언트가 메세지 요청
- 서버가 메세지 응답
- HTTP 서버 닫음
- 클라이언트가 응답 받고 데이터 얻음
비 지속 연결의 경우, 총 10개의 이미지면 11번의 연결과 해제가 필요함
RTT (Round - Trip - Time)
서버한테 패킷을 보내고 돌아오는 시간

비 지속 연결의 경우
HTTP 응답시간 = 2RTT + 파일전송시간
HTTP 1.1 (지속 연결)
파이프라인 방식, TCP 연결을 유지함
비지속 연결의 각 객체마다 2RTT씩 시간 발생이 비효율적임
참조된 모든 객체, 각각 단 한 번의 RTT만 필요 (절반 단축)
HTTP 1.1 단점
HTTP 1.1은 단일 TCP 연결로, 10개 데이터를 주고 받으려면 10개의 TCP 연결
큰 객체가 전송 중이면, 작은 객체는 계속 기다려야 함
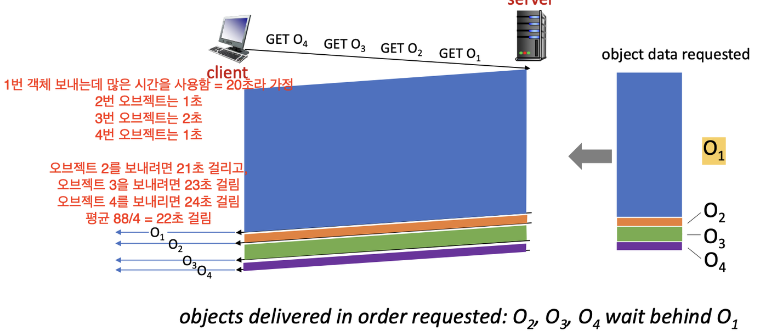
O2, O3, O4는 간단한 건데도 계속 기다림
HTTP 메소드 & 에러코드
HTTP 메세지는 2종류, Request와 Response이다.
- Post
- Get
- Put
- Delete
- 200 - 정상
- 301 - 이동됨
- 400 - 잘못된 형식
- 404 - 요청한 정보를 서버로부터 찾을 수 없음
쿠키
HTTP는 Stateless이다.
어떻게 자동 로그인이 웹에서 가능할까 ?
→ 웹 사이트와 클라이언트 브라우저는 쿠키로 트랙잭션 일부 상태를 유지
클라이언트는 요청할 때, 쿠키도 같이 보냄
서버는 쿠키를 읽고 구체적으로 답변
쿠키는 웹에서 내가 하는 행동을 읽는데,
내가 방문하지 않은 사이트여도 쿠키를 받을 수 있음
웹 캐시 (proxy servers)
최근 호출된 객체의 사본 저장 및 보존
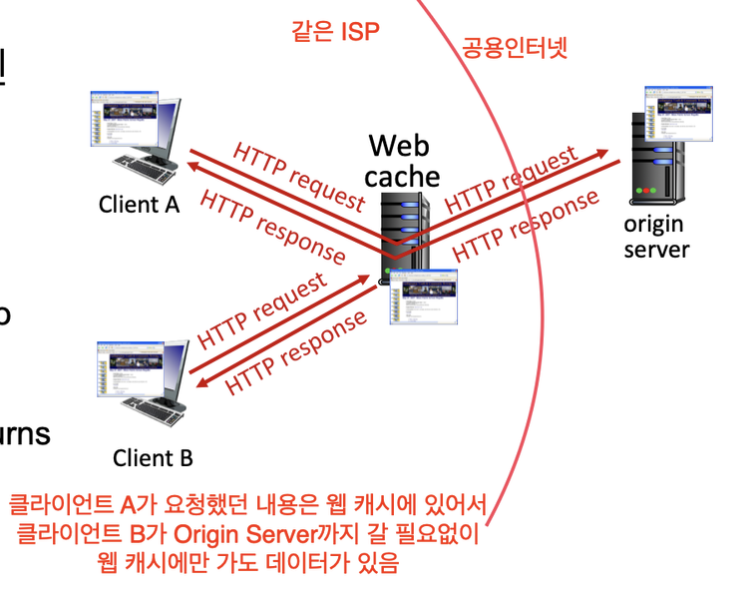
클라이언트 A가 이미 서버로부터 데이터를 가져오면,
클라이언트 B가 동일한 데이터를 서버에 요청하면, 웹 캐시로부터 가져옴
웹 캐시 사용 이유
- 클라이언트의 요구에 대한 응답 시간 감소
- 전체 트래픽 감소
- 데이터 센터가 없는 가난한 컨텐츠 제공 업체 지원
조건부 GET
웹 캐시 단점으로, 서버와 비교해서 최신 데이터가 아닐 수 있음
헤더만 보내서 최신 데이터가 맞는지 확인함 → 트래픽 양 부담 적음
HTTP 2.0
HTTP 1.1에서 유연성 증가가 됐음
HTTP 1.1과 달리 바뀐 점
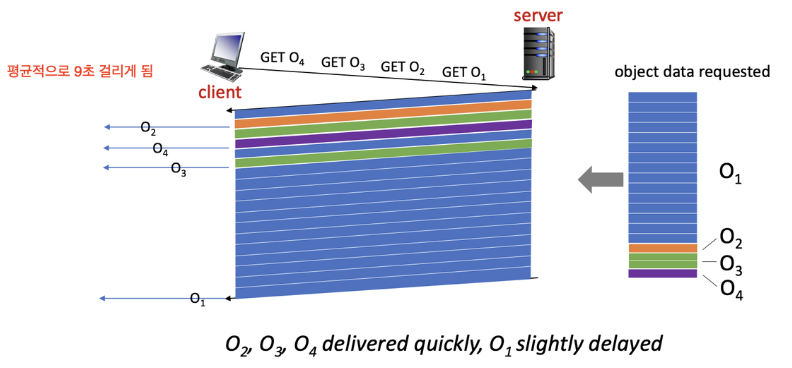
- 요청 순위 우선화
클라이언트가 지정한 객체 우선순위에 따라 전송 순서 결정 - 서버 푸쉬
클라이언트가 요청하지 않는 객체를 서버가 먼저 보내줌 - 효율적인 헤더 전송
중복 헤더 제거, 헤더 압축 - 프레이밍
데이터를 쪼개서 보냄
HTTP 2.0 단점
- 패킷 손실 복구는 여전히 모든 객체 전송을 지연시킴
- 일반 TCP 연결에 보안을 제공하지 않음
HTTP 3.0
보안성 추가 및 객체별로 에러, 혼잡도 조작
'Computer Science > Computer Network' 카테고리의 다른 글
| [CN] 2장: The Domain Name System, DNS (0) | 2024.05.13 |
|---|---|
| [CN] 2장: E-mail, SMTP, IMAP (0) | 2024.05.11 |
| [CN] 2장: Principles of network applications (0) | 2024.05.10 |
| [CN] 1장: 프로토콜 계층, 서비스 모델 & 보안 (0) | 2024.05.09 |
| [CN] 1장: Performance: Loss, Delay, Throughput (0) | 2024.05.07 |