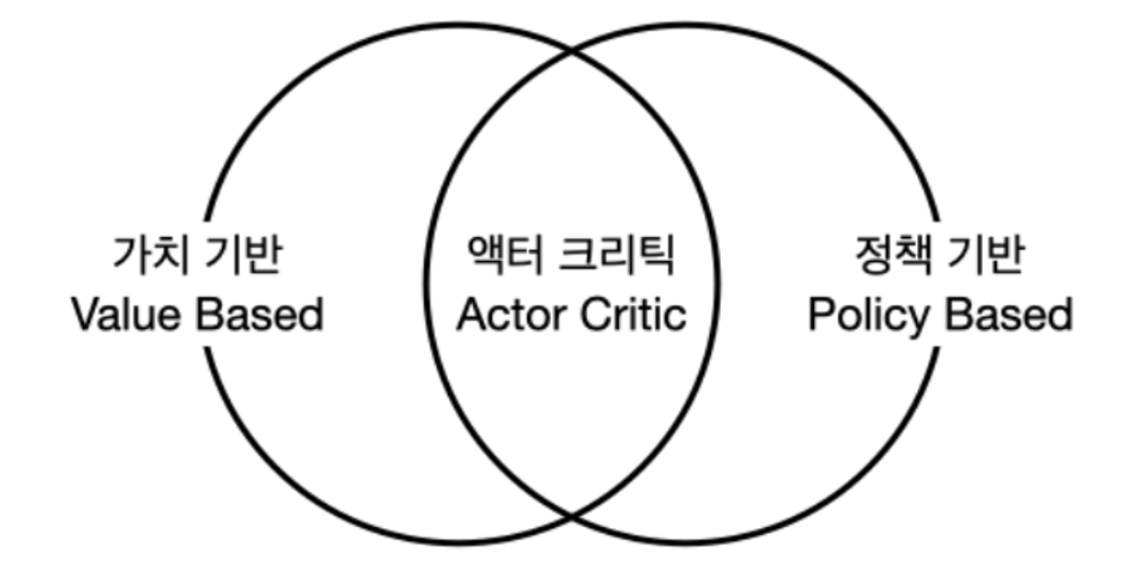
에이전트 3가지 종류액션을 정하는 기준에 따라 에이전트 3종류를 구분할 수 있음1. 가치 기반 에이전트: 가치함수에 근거하여 액션을 선택 모델 프리 상황에서는 상태 가치함수만으로 액션을 선택할 수 없음. 액션 가치함수를 근거하여 액션을 선택2. 정책 기반 에이전트: 정책함수 π(a∣s)를 보고 액션을 선택 -> 다음 챕터에서 다룸3. 액터-크리틱: 가치함수 + 정책함수 모두 사용, Actor는 행동하는 주체, Critic은 비평가, (즉 상태가치 + 액션가치) ..