에이전트 3가지 종류
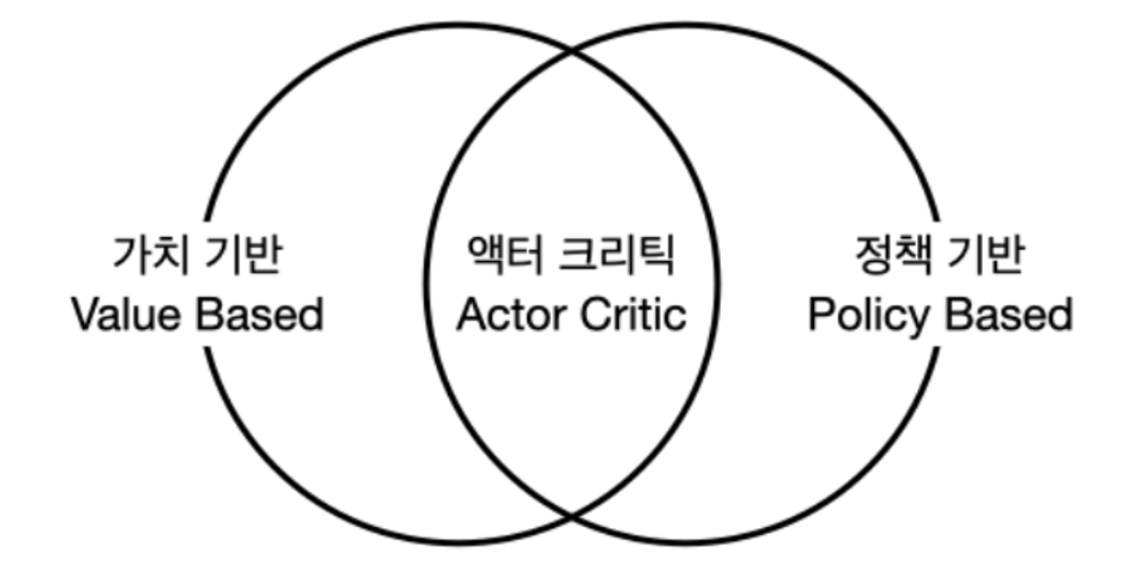
액션을 정하는 기준에 따라 에이전트 3종류를 구분할 수 있음
1. 가치 기반 에이전트: 가치함수에 근거하여 액션을 선택
모델 프리 상황에서는 상태 가치함수만으로 액션을 선택할 수 없음.
액션 가치함수를 근거하여 액션을 선택
2. 정책 기반 에이전트: 정책함수 π(a∣s)를 보고 액션을 선택
-> 다음 챕터에서 다룸
3. 액터-크리틱: 가치함수 + 정책함수 모두 사용,
Actor는 행동하는 주체, Critic은 비평가, (즉 상태가치 + 액션가치)
-> 다음 챕터에서 다룸벨류 네트워크 학습

정책 π가 고정되어 있을 때 뉴럴넷을 이용하여 π의 가치 함수 Vπ(s) 학습하는 방법
밸류 네트워크(value netowrk)
: 뉴럴넷으로 이루어진 가치 함수 vθ(s)
(θ는 신경망의 파라미터)손실함수: 예측한 값이 실제와 얼만큼 차이나는가, 작을 수록 좋음
손실함수 정의
: 뉴럴넷 학습시키려면 손실함수를 정의
Vtrue(s) = 실제 상태의 가치 함수
Vθ(s) = 파라미터에 대한 상태 가치함수
-> 손실함수를 최소화하는 방향으로 θ를 업데이트 하도록 학습하면 됨모든 상태에 대해서 적용하면 좋겠지만 존재는 모든 상태를 방문해 볼 수 없으니 이를 실제로 계산하기 어려움
따라서 기대 값을 사용
π를 이용해 데이터를 열심히 모으고, 그 데이터를 이용해 학습 하면 된다.
손실 함수에서 π가 자주 방문 하는 상태 가중치는 더 높아지고
π가 거의 방문 하지 않는 상태 가중치는 낮아 진다는 점이다정의된 손실함수 L(θ)를 θ에 대해 편미분을 통해 그라디언트를 계산
(상수 2는 생략, 나중에 알파값을 통해 조절할 수 있음)
위 식을 통해 파라미터를 갱신해나감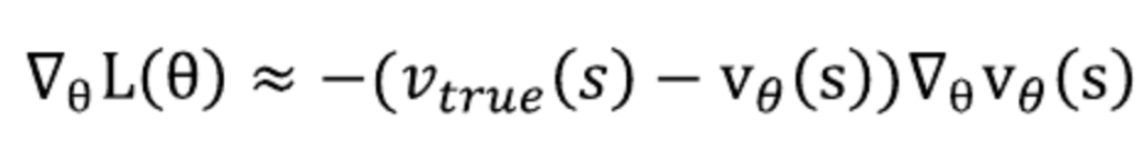
위의 미분결과식을 실제 계산하기 위해서는 정책 π를 근거로
액션을 취하는 에이전트를 통해 상태 S 샘플을 뽑는다.
충분히 반복해서 실행하면서 아래 우변 수식을 계산하여 평균을 내면
결국 좌변 즉 손실함수의 θ에 대한 미분에 근사한 결과를 갖게 된다.
정리
정책 π를 근거로 해서 여러 번 샘플링하여 기댓값을 보면
손실함수의 θ에 대한 근사치를 얻게됨
파라미터는 위와 같이 갱신해 나간다.
위 결과값을 이용해서 θ값을 업데이트
-> 이 과정을 반복해서 손실함수가 최소화되는 θ를 구할 수 있게 됨
즉, 실제 가치함수에 근사한 가치함수를 구할 수 있게 된다.
그러나, 문제는 실제 가치함수를 알 수가 없음 (Vtrue)
정답을 모르니 신경망을 통한 학습을 할 수가 없게 됨
이때, MC의 리턴과 TD의 타깃을 활용할 수 있음첫 번째 대안: 몬테카를로 리턴

(좌) MC 이론 | (우) 몬테카를로 리턴
우리가 구하려고 하는 실제 가치함수 Vtrue(s)는
뉴럴 네트워크에서도 결국 리턴의 기댓값에 해당함 (Gt)
즉, V_true(s) 대신 관측된 Gt를 사용한다면,
뉴럴넷의 아웃풋이 실제 가치에 수렴할 것이라 예상할 수 있음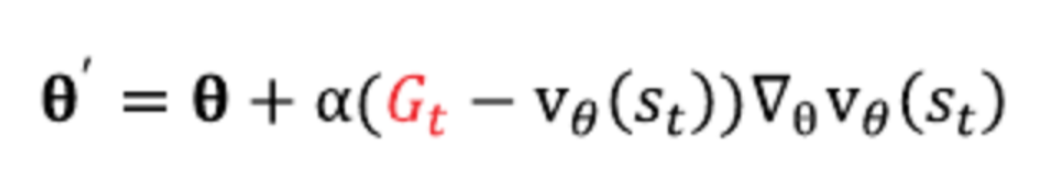
특정 파라미터 θ는 위와 같이 업데이트 가능
충분히 반복적으로 에피소드를 실행해가며
한 에피소드가 끝날 때마다 모인 샘플 상태 S들의 리턴값을 활용해 손실 함수의 파라미터 θ를 업데이트
즉, 하나의 에피소드가 끝나야 업데이트가 진행되어 실시간 업데이트는 불가능하고,
리턴의 분산이 크다는 점에서 MC와 동일한 특성을 지니고 있음두 번째 대안: TD 타깃
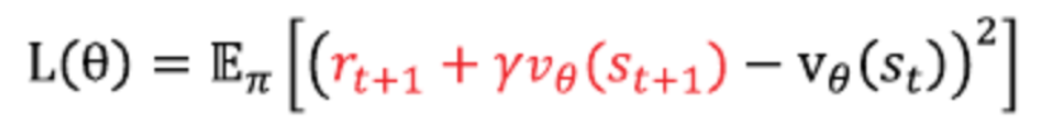
Gt 자리에 TD 타깃을 대입하면 됨
손실함수는 위와 같이 정의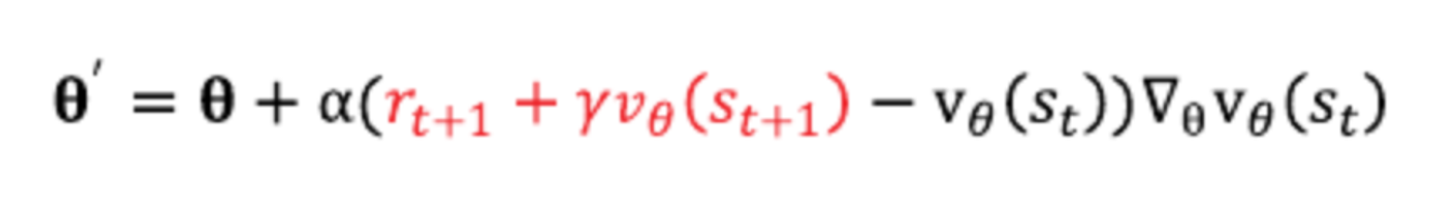
업데이트 식에서 TD 타깃 부분은 상수
업데이트 할 당시의 θ 파라미터 값을 이용해 vθ(st+1)이 계산되어지며 상수가 되므로
미분하면 0이 되면서 미분 대상에서 제외됨
목적지 값을 상수로 취급해야 안전하게 학습이 가능하다.딥 Q러닝 개요
가치 기반 에이전트는 π가 없음
대신 액션 가치함수 q(s, a)를 통해 밸류를 계산하고,
각 상태에서 q가 가장 높은 액션을 선택하는 정책을 사용
챕터 6의 Q러닝에서 언급한 내용이나, 전제조건이 규모가 큰 MDP로 변경
따라서 테이블 기반 방법론으로 Q값을 저장 및 업데이트할 수 없으며
신경망을 이용해서 q(s, a)를 표현딥 Q러닝 이론적 배경
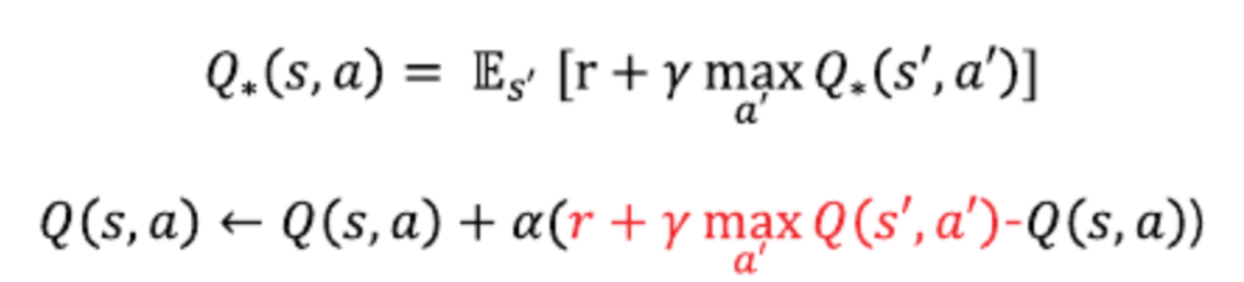
벨만 최적 방정식과 이를 이용한 테이블 업데이트 수식
Q러닝은 벨만 최적 방정식을 통해 Q*(s, a)를 학습했으니,
딥 Q러닝도 마찬가지로 정답을 r + γ * max Q(s′,a′)로 본다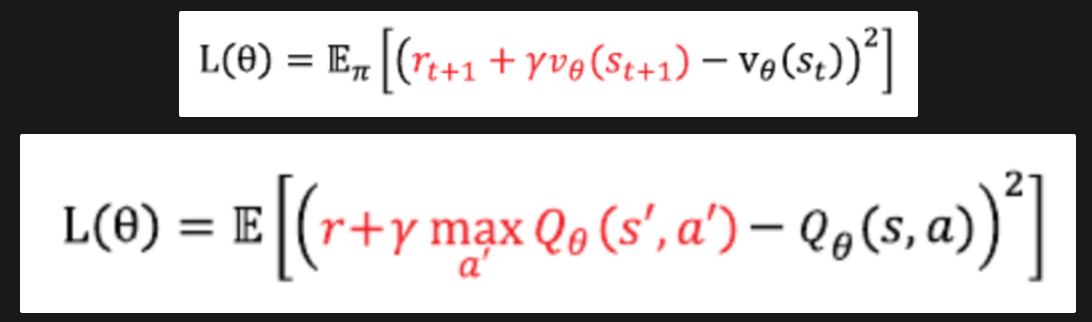
벨만 최적 방정식을 통해
손실함수 재정의
손실함수의 미분을 진행한 후 파라미터 θ의 업데이트 수식은 위와 같음
위 수식을 통해 θ 파라미터를 계속 업데이트 하면
Qθ(s, a)는 점점 최적의 액션-가치함수 Q∗(s,a)에 가까워짐부 교재의 딥 Q러닝 로직
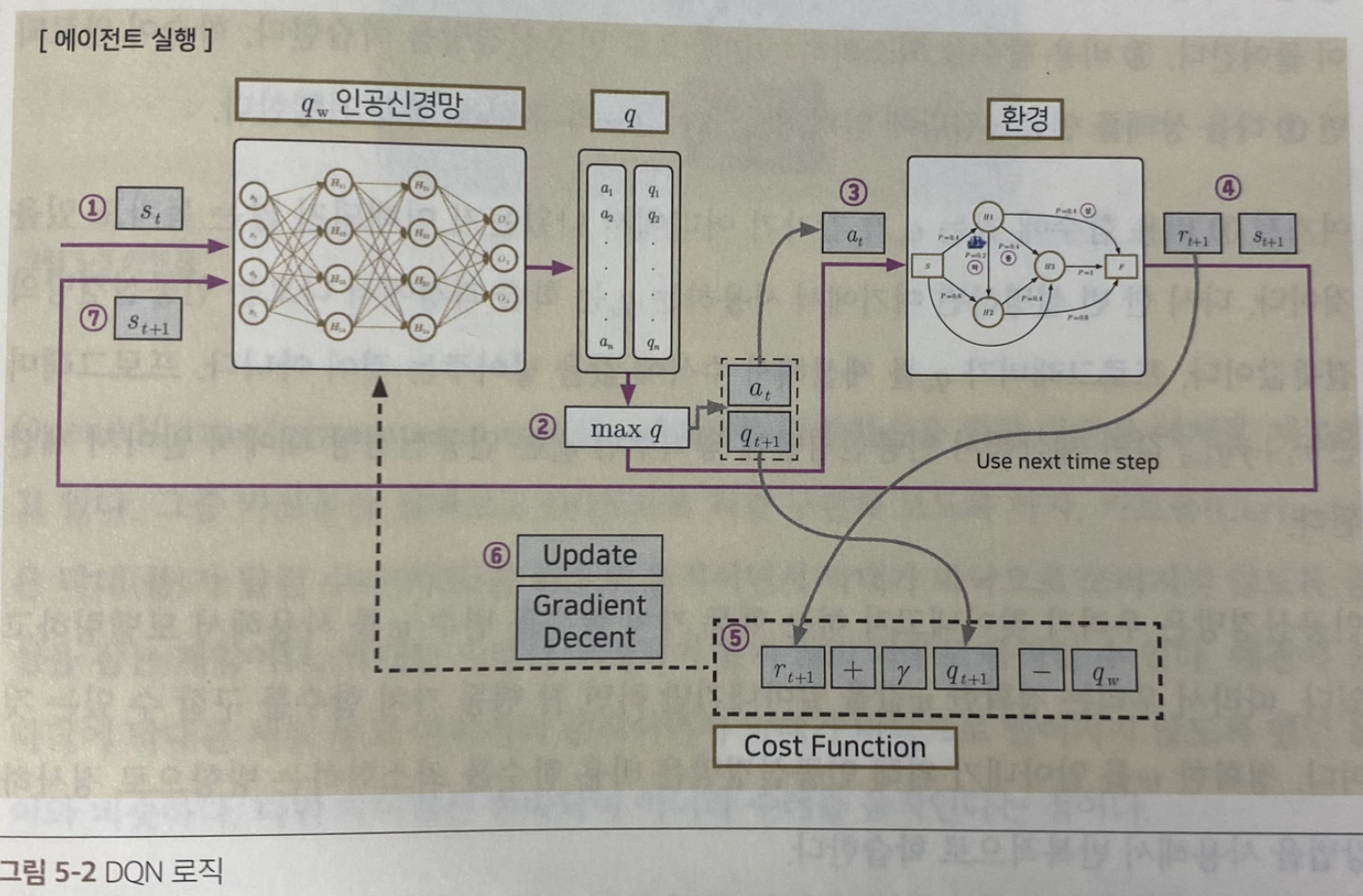
- 행동 선택을 위해 Q러닝에서는 q값을 계산해야 하는데, 이는 인공신경망이 지니고 있음
- 상태를 입력하면 결과로 행동(a)와 q값을 행렬 형태로 반환됨
- 가장 큰 q값을 가지고 있는 행동을 찾아냄 = max q
- 에이전트는 그 행동(max q)에 따라 동작을 수행
- 에이전트가 동작을 수행한 후 환경에서는 그에 따른 보상(r+1)와 다음 상태(St+1)을 반환
- 현재 상태의 큐(q) 값과 보상(r)을 얻었기에 손실 함수를 다시 계산하게 됨
이때 비용 함수에 들어가는 보상은 다음 타입스텝(t+1)이 아닌, 이전 타입스텝(t)에서 얻은 보상이 들어감 - 손실 함수를 최소화하는 방향으로 인공신경망을 학습
- 학습이 완료되면 다음 상태를 인공신경망에 입력해서 에이전트 훈련을 계속 진행
*5번에서 나온 qθ는 학습 과정에서 나오는 인공 신경망의 결괏값이다. (우리가 계산하는 게 아님)
본 교재의 딥 Q러닝 로직

환경에서 실제로 실행할 액션을 선택하는 부분은 3-A,
TD 타깃 값을 계산하기 위한 액션을 선택하는 부분은 3-C
3-C에서 선택한 액션은 실제로 실행되지 않으며 업데이트를 위한 계산에만 사용된다
=> Off-policy 학습 특성
실행할 액션을 선택하는 행동 정책은 ϵ - greedy Qθ(3-A)단계 이고,
업데이트시 사용되는 정책은 greedy Qθ(3-C) 로 서로 다르다익스피리언스 리플레이와 타깃 네트워크
Deep Q러닝을 기본으로 하는 DQN 알고리즘에서
안정적인 학습과 성능을 위해 추가로 사용되는 2가지 방법론익스피리언스 리플레이
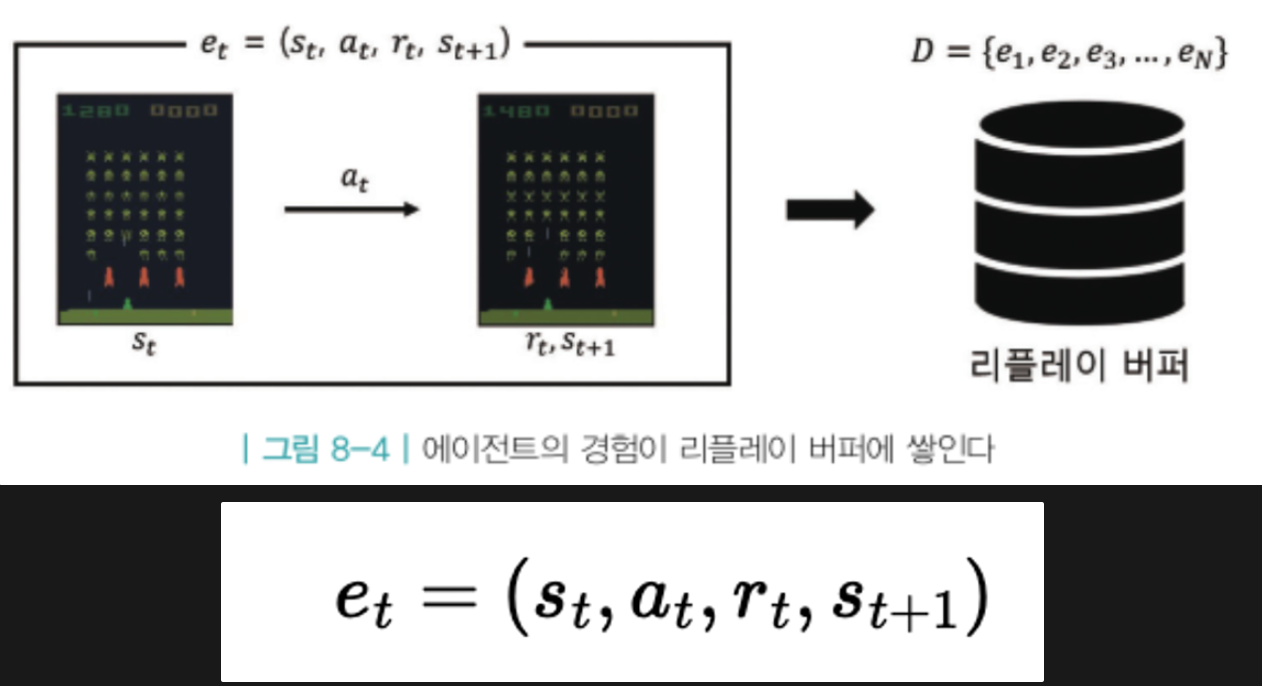
겪었던 경험을 재사용하자는 아이디어에서 시작됨
경험 = 에피소드
에피소드는 여러 개의 상태전이로 구성되는데, 각각의 상태 전이는 위 et 식과 같다.
'상태 st에서 액션 at를 했더니 보상 rt을 받고 다음 상태 st+1에 도착하였다'
하나의 상태전이를 하나의 데이터로 볼 수 있음
이러한 상태전이 데이터를 최근 기준으로 N개를 버퍼에 저장해두고,
학습할 때 이 버페에서 정한 개수만큼 상태전이 데이터를 뽑아서 학습에 리플레이 식으로 사용
재사용성으로 효율성 증대 + 랜덤 상태전이 데이터 추출하여 데이터 사이 상관성도 줄여준다고 함
이 방법은 Off-Policy 알고리즘에만 사용 가능
리플레이 버퍼에 저장된 상태전이 데이터들은 과거 정책에 따라 생성된 데이터이고,
그것을 현재 새로운 타깃 정책에 개선하려 하기 때문별도의 타깃 네트워크
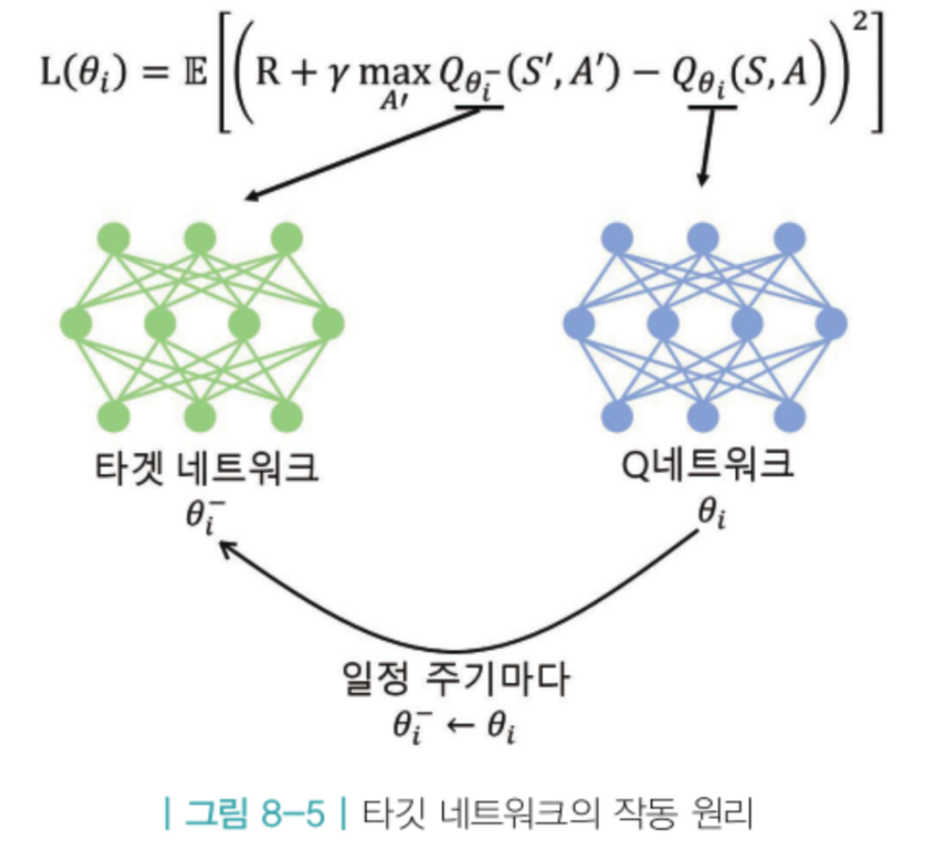
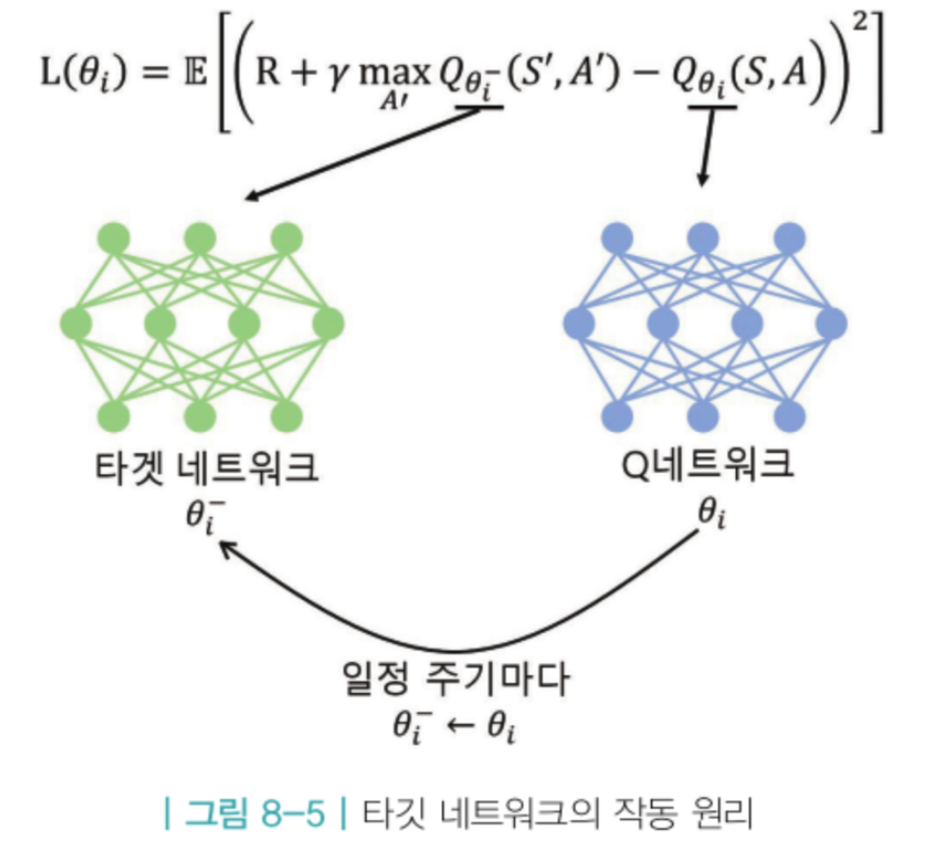
딥 Q러닝에서 손실함수 L의 의미는 정답과 추측 사이의 차이,
이를 줄여가는 방향으로 파라미터가 업데이트 됨
Q 러닝의 정답부분은 파라미터에 의존적임
학습을 하면서 신경망을 통해 파라미터가 업데이트 되고, 결국 정답에 해당하는 값이 변경
이처럼 신경망 학습과정에서 정답이 변하는 것은 성능을 떨어뜨림
-> 타깃 네트워크 방법 등장
정답을 계산할 때 사용하는 타깃 네트워크와 학습을 받는 Q 네트워크로 구성
정답을 계산할 때 사용되는 타깃 네트워크의 파라미터들은 일정기간 변경하지 않게 함
이를 얼린다고 표현함
그 사이, Q 네트워크의 파라미터는 계속해서 업데이트 진행
ex) Q 네트워크에서 1천번 파라미터를 업데이트한 후,
타깃 네트워크의 얼린 파라미터를 현재 시점의 Q 네트워크 파라미터로 업데이트
-> 성능이 대폭 개선되었다고 함카트폴 문제 DQN 구현
카트 위에 막대를 세우고, 카트를 움직여서 막대가 넘어지지 않게 균형을 잡는 문제
에이전트 = 카트
액션 = 좌로 이동, 우로 이동 2가지
각 스텝마다 보상 = +1, 가능한 오래 균형을 잡으면 보상이 최대가 됨
종료 시점 = 막대가 수직으로부터 15도 이상 기울어지거나, 카트가 화면 끝으로 나가면 종료
카트 상태 S = (카트의 위치정보, 카트의 속도정보, 막대의 각도, 막대의 각속도)코드 구현
import gym # OpenAI GYM 라이브러리
import collections # deque 활용
import random
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# 하이퍼 파라미터 정의
learning_rate = 0.0005
gamma = 0.98
buffer_limit = 50000
batch_size = 32
# 리플레이 버퍼 클래스
class ReplayBuffer:
def __init__(self):
self.buffer = collections.deque(maxlen=buffer_limit)
# 최신 상태전이 데이터를 버퍼에 넣어줌
# 버퍼가 꽉 찼을 때 더 들어오면, 버퍼가 밀려남
def put(self, transition):
self.buffer.append(transition)
# 버퍼에서 배치크기(32)만큼 데이터를 뽑아서 미니배치를 구성
# 데이터는 (s, a, r, s_prime, done_mask)로 구성
# done_mask = 현재 상태의 종료 여부로 종료는 0, 나머지 상태는 1
def sample(self, n):
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [], [], []
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
done_mask_lst.append([done_mask])
return (np.array(s_lst, dtype=np.float32), np.array(a_lst, dtype=np.int32),
np.array(r_lst, dtype=np.float32), np.array(s_prime_lst, dtype=np.float32),
np.array(done_mask_lst, dtype=np.float32))
def size(self):
return len(self.buffer)
# Q밸류 네트워크 클래스
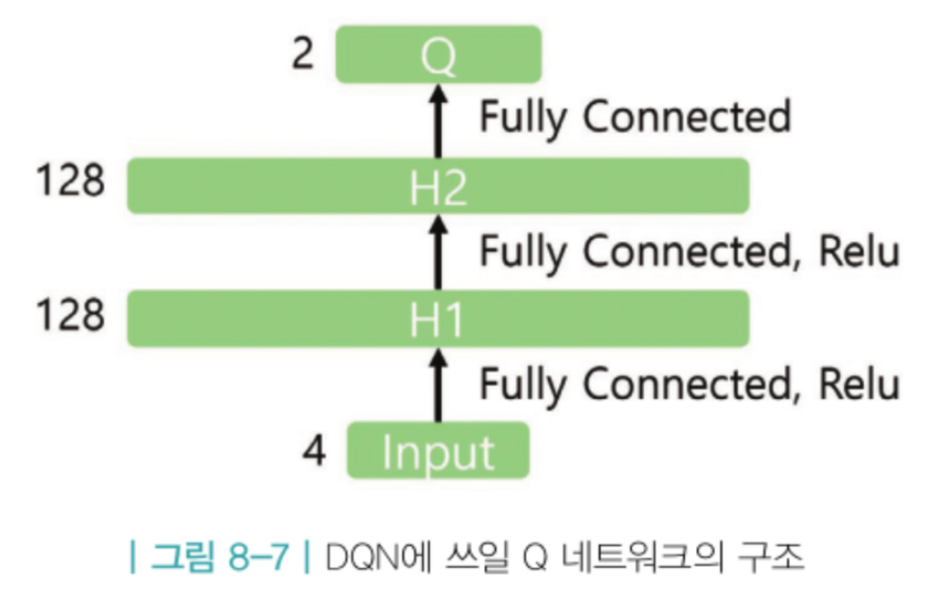
class Qnet(models.Model):
def __init__(self):
super(Qnet, self).__init__()
self.fc1 = layers.Dense(128, activation='relu')
self.fc2 = layers.Dense(128, activation='relu')
self.fc3 = layers.Dense(2, activation=None)
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def sample_action(self, obs, epsilon):
out = self.call(obs)
if random.random() < epsilon:
return random.randint(0, 1)
else:
return np.argmax(out.numpy())
# Q 네트워크 학습 함수
# 하나의 에피소드가 끝날 때마다 train 함수가 호출 -> 네트워크 가중치 업데이트
# 함수 내부에서는 버퍼에서 10개의 미니 배치를 얻어와서 학습을 진행 (한 개당 32개 데이터)
def train(q, q_target, memory, optimizer):
for i in range(10): # 10번 반복
s, a, r, s_prime, done_mask = memory.sample(batch_size)
# Replay Buffer에서 미니 배치(batch_size: 32) 샘플링
# s: 상태, a: 행동, r: 보상, s_prime: 다음 상태, done_mask: 에피소드 종료 여부
with tf.GradientTape() as tape:
q_out = q(s) # 현재 상태 S에 대한 Q-값 계산 = 현재 네트워크 q를 통해 계산
q_a = tf.gather_nd(q_out, indices=np.expand_dims(a, axis=1), batch_dims=1)
# 선택한 행동 a에 대한 Q-값 추출
max_q_prime = tf.reduce_max(q_target(s_prime), axis=1, keepdims=True)
# 다음 상태에 대한 최대 Q-값 계산 (타겟 네트워크 사용)
target = r + gamma * max_q_prime * done_mask
# 목표값 계산: r + γ * max(Q(s', a'))
loss = tf.reduce_mean(tf.square(target - q_a))
# 손실 함수: (목표값 - 예측값)의 제곱의 평균
grads = tape.gradient(loss, q.trainable_variables)
# 손실 함수에 대한 네트워크 가중치의 그래디언트 계산
optimizer.apply_gradients(zip(grads, q.trainable_variables))
# 계산된 그래디언트를 사용하여 네트워크 가중치 업데이트
# 메인 함수
def main():
env = gym.make('CartPole-v1')
q = Qnet()
q_target = Qnet()
# 모델 빌드
q.build(input_shape=(None, 4))
q_target.build(input_shape=(None, 4))
q_target.set_weights(q.get_weights())
memory = ReplayBuffer()
print_interval = 20
score = 0.0
optimizer = optimizers.Adam(learning_rate)
for n_epi in range(10000):
epsilon = max(0.01, 0.08 - 0.01 * (n_epi / 200))
s = env.reset()
done = False
while not done:
a = q.sample_action(np.array([s], dtype=np.float32), epsilon)
s_prime, r, done, _ = env.step(a)
done_mask = 0.0 if done else 1.0
memory.put((s, a, r / 100.0, s_prime, done_mask))
s = s_prime
score += r
if done:
break
if memory.size() > 2000:
train(q, q_target, memory, optimizer)
if n_epi % print_interval == 0 and n_epi != 0:
q_target.set_weights(q.get_weights())
print("n_episode : {}, score : {:.1f}, n_buffer : {}, eps : {:.1f}%".format(
n_epi, score / print_interval, memory.size(), epsilon * 100))
score = 0.0
env.close()
if __name__ == '__main__':
main()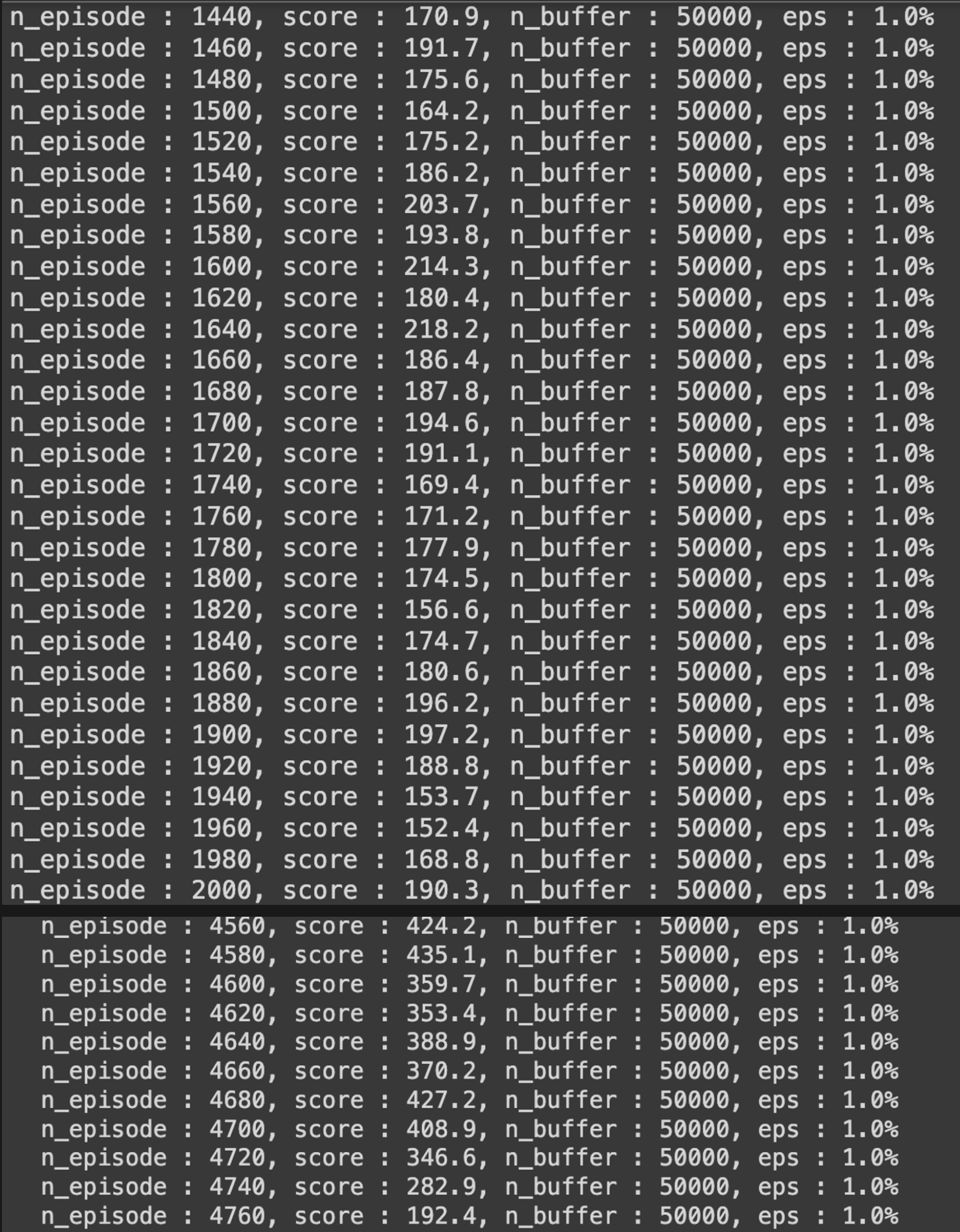

'🎸 기타 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Deep RL 첫 걸음 (0) | 2024.06.05 |
|---|---|
| [RL] MDP를 모를 때 최적의 정책 찾기 (1) | 2024.06.03 |
| [RL] MDP를 모를 때 밸류 평가하기 (1) | 2024.06.02 |
| [RL] MDP를 알 때 플래닝 (0) | 2024.05.23 |
| [RL] 벨만 방정식 (0) | 2024.05.20 |